
5 ways to store market data: CSV, SQLite, Postgres, Mongo, Arctic
What's the most efficient way to store market data? SQL or NoSQL? Let's compare 5 most common options and find out what is best.


What’s the best way to store market data?
Well, it depends on a combination of factors. Among the most important, I will name dataset size, read and write queries frequency, and desired latency.
So let’s dive in and build an app to perform a considerable amount of CRUD operations and connect it to different databases. We will use plain CSV files, relational databases SQLite and Postgres, and non-relational databases Mongo and Arctic.
Github repo.
We will measure the time of execution of the following operations:
- append 1k records one by one,
- bulk save 1M records,
- read the entire database with 1M records,
- make a single query to the database with 1M records
We will also compare the database size of 1M records datasets.
To produce that 1M records, we will use the synthetic data generator described here.

Let’s make an overview of possible data storage options. CSV files are a fast and comfortable way to work with spreadsheet data, but it’s not great as permanent data storage. SQLite needs no setup and is quick and stable – probably the best option for small projects. Postgres is an open-source production-ready database with lots of use cases. Mongo is a NoSQL alternative that can sometimes be much faster than SQL databases. Arctic is built upon Mongo to make it even more helpful for those who work with market data, as Arctic supports pandas dataframes and NumPy arrays by default.
Now let’s talk about our app.
We will create five connectors to five different data storages. They will consist of four classes: Connector, ReaderApp, WriterApp, and ServiceApp. This time, we will build some connectors from scratch instead of using SQLAlchemy for educational purposes.
The connector class will contain service data like filenames and methods to create tables.
ReaderApp will contain methods to read data from the database and to make a query.
class ReaderApp:
__metaclass__ = ABCMeta
@abstractmethod
def read_all_data(self):
'''reads all data from file/database'''
raise NotImplementedError("Should implement read_all_data()")
@abstractmethod
def read_query(self):
'''makes a specific query to file/database '''
raise NotImplementedError("Should implement read_query()")
WriterApp will save data to the database.
class WriterApp:
__metaclass__ = ABCMeta
@abstractmethod
def append_data(self):
'''saves data line by line, like in real app '''
raise NotImplementedError("Should implement save_data()")
@abstractmethod
def bulk_save_data(self):
'''save all data at one time '''
raise NotImplementedError("Should implement bulk_save_data()")
And ServiceApp will be responsible for clearing databases and statistics, including database size.
class ServiceApp:
__metaclass__ = ABCMeta
@abstractmethod
def clear_database(self):
raise NotImplementedError("Should implement clear_database()")
@abstractmethod
def size_of_database(self):
raise NotImplementedError("Should implement size_of_database()")
After all those classes are built, we can use them in our main app, MultiDatabaseApp. It will generate synthetic data, perform CRUD operations, measure execution time, and plot charts to visualize results.
The most pythonic way to measure execution time is to use a decorator function. It simply makes something before and after launching the ‘decorated’ part.
def execution_time(func):
#measures a database operation execution time
def measure_time(*args, **kwargs) -> dict:
start_time = time.time()
response = func(*args, **kwargs)
execution_time = time.time() - start_time
response['execution_time'] = execution_time
return response
return measure_time
The code is available here.
Now all preparations are ready, and we can start!

The first action is to bulk save 1 million synthetic ticks. Both Postgres and Mongo work slowly. All database server’s settings are default, which could be the reason. Arctic is the leader here!
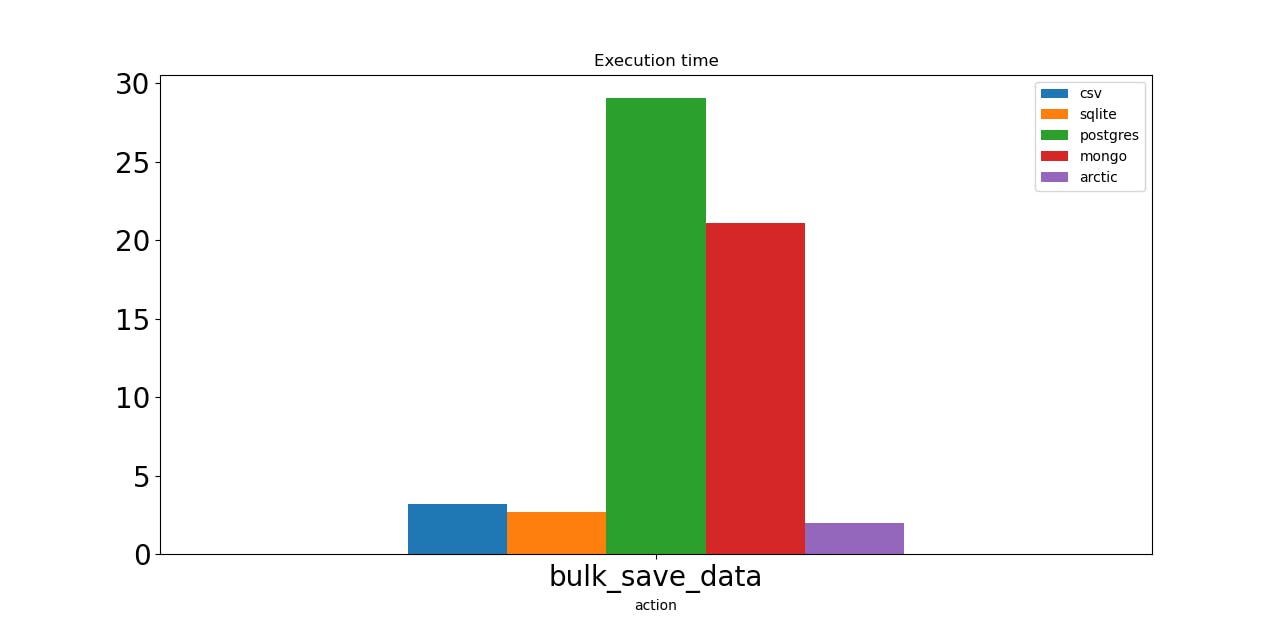
Both CSV and SQLite are almost as fast as Arctic.

The next test is appending 1000 ticks one by one. And again, Postgres is the worst option. Mongo is the leader here; we can choose it if we need to save data frequently. Arctic, built on Mongo, should have the same speed. Still, I was using VersionStore with 1 million already added data points, so Arctic reads that data each time, appends one, and saves.
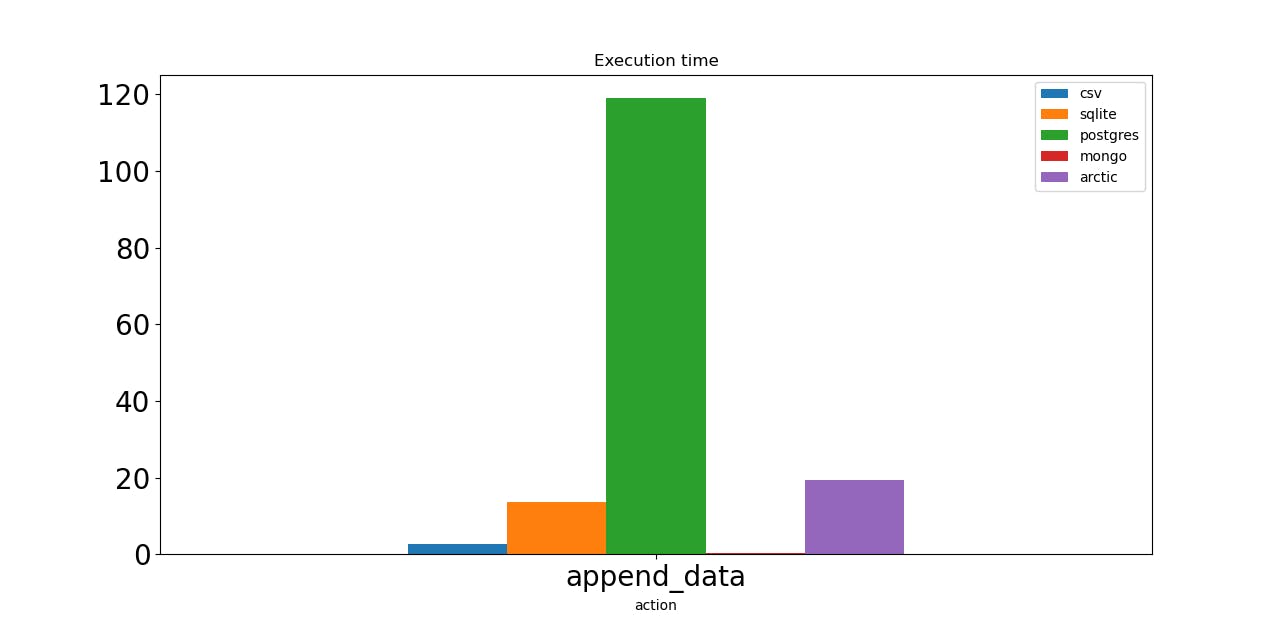
Both CSV and SQLite show decent results.

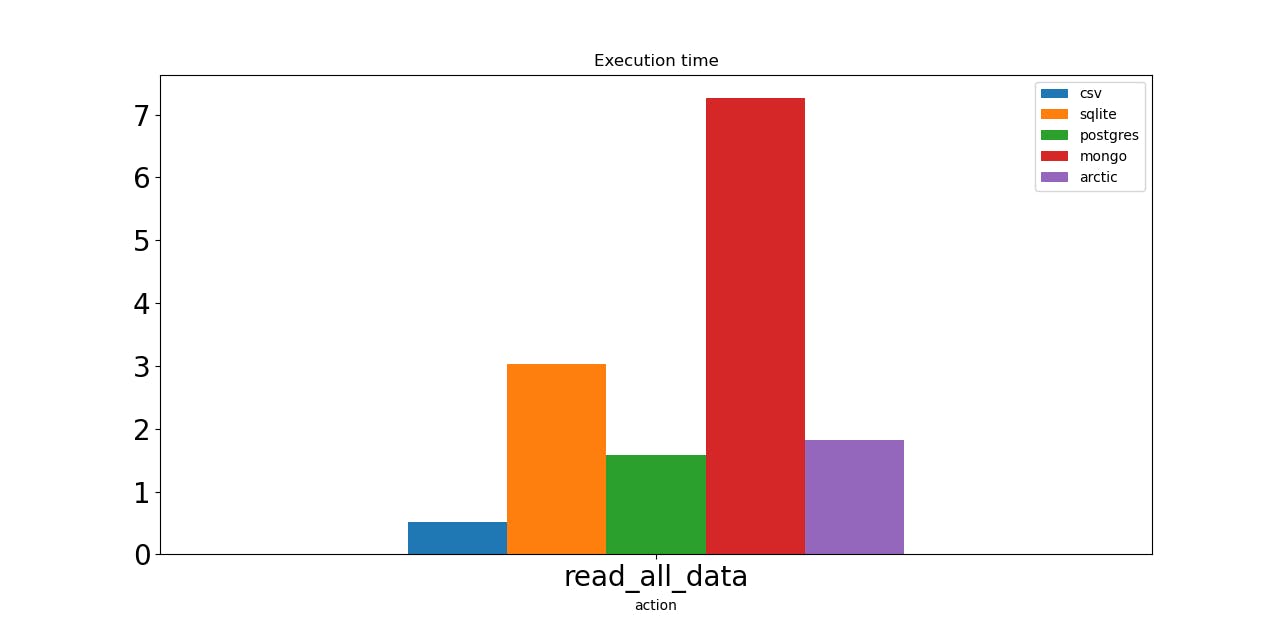
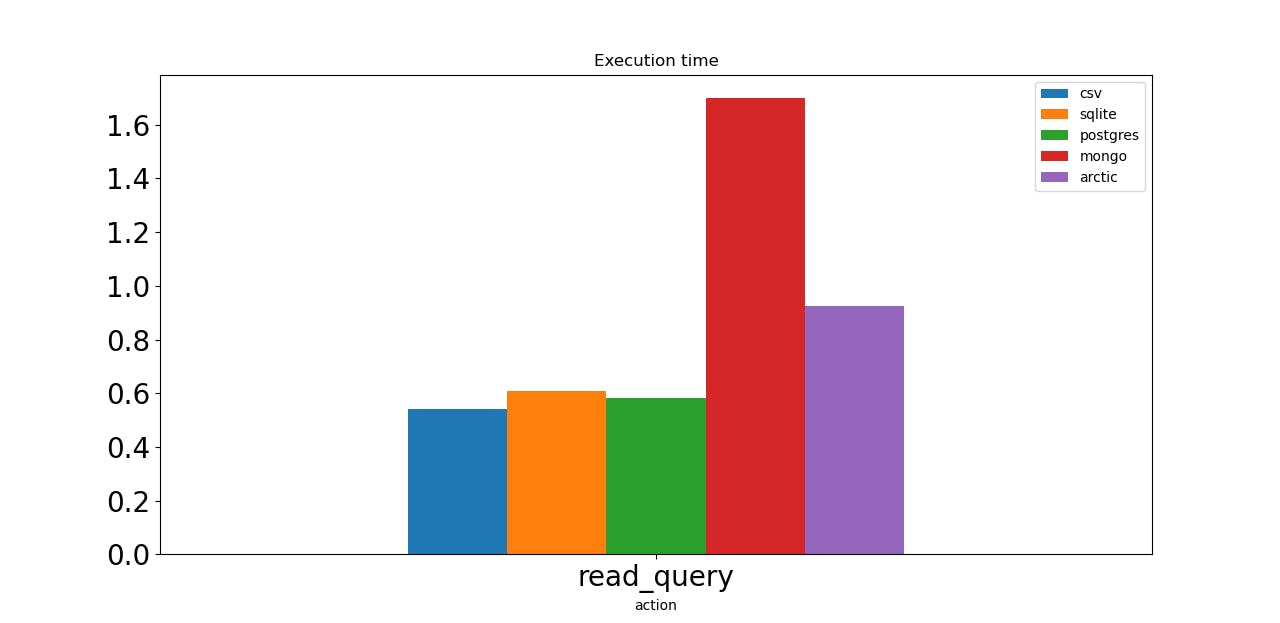
Now let’s check the read operations speed. The first is just a query to read the whole dataset. CSV shows the best result. The operation is complete in less than 1 second! Postgres and Arctic need almost 2 seconds, SQLite – 3 seconds. Mongo is the slowest horse, with 7 seconds.

The next operation to test is a query to select only those rows where the Bitcoin price is less than 20155. SQL databases are fast enough, the same as CSV files. Mongo and Arctic need more time to get data from the database.

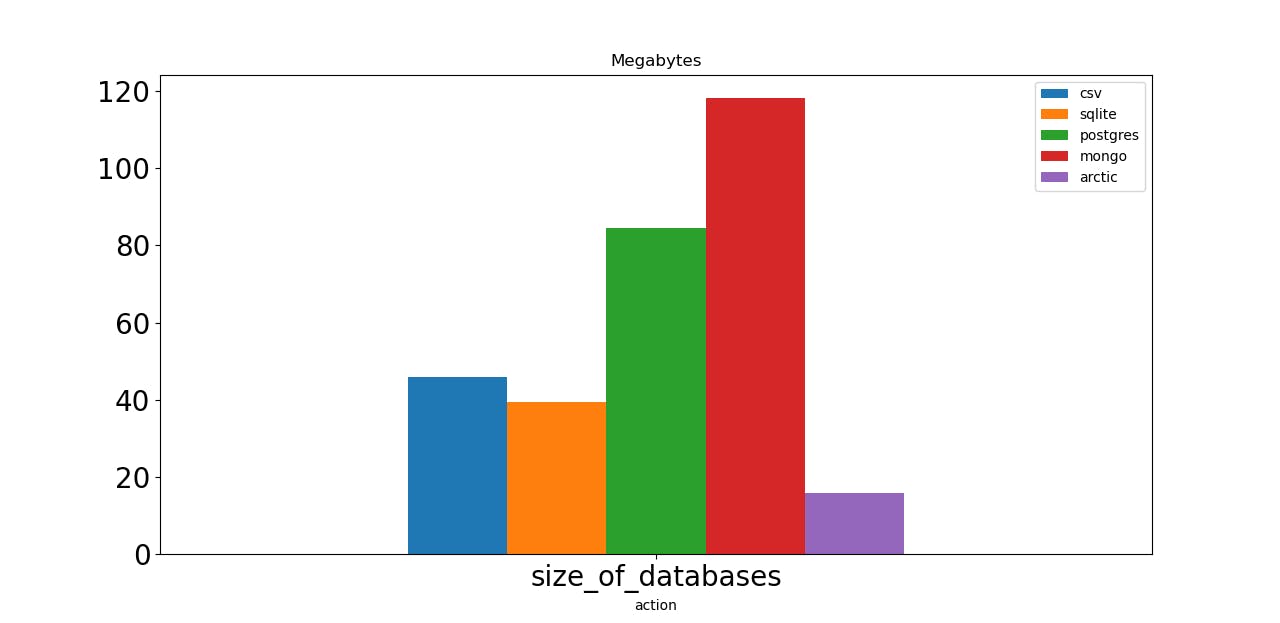
Now let’s check our database’s sizes. Arctic is at least two times better than any competitor. What a great result! CSV and SQLite databases are medium sizes, about 40Mb each. Postgres and Mongo need about 100Mb to store the same amount of data, which means that if we are limited with disk space or bandwidth usage, we have to consider other options.

Now let’s have a look at creating operations execution time once more.
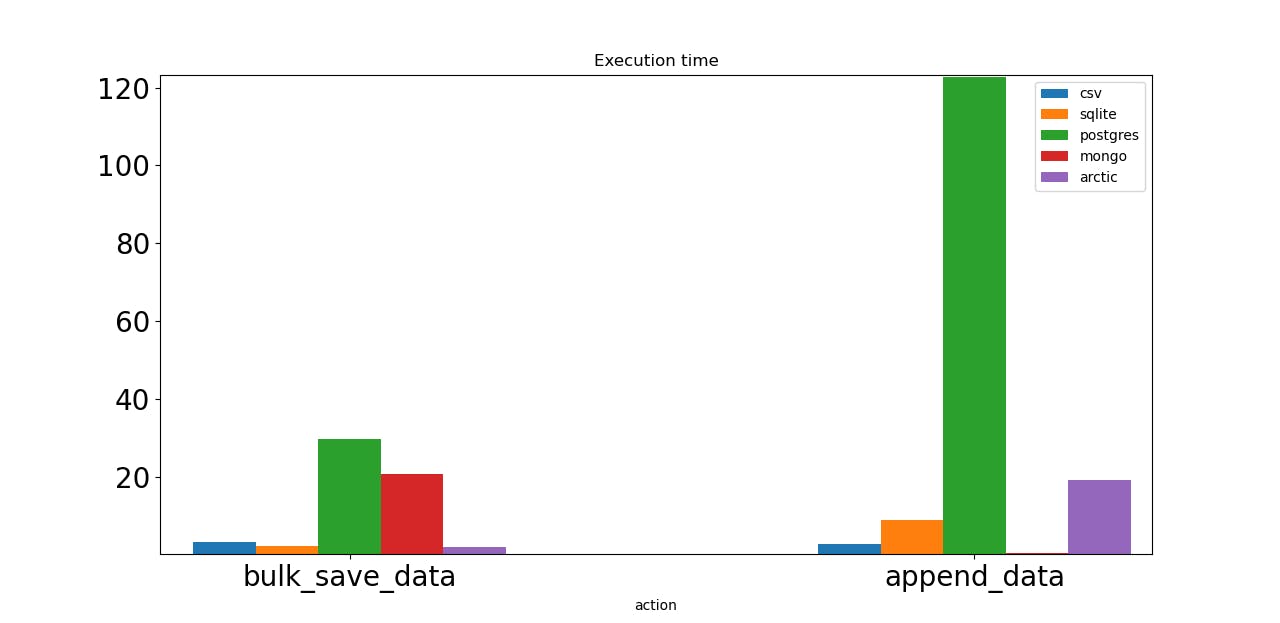
Mongo and Arctic can be our choice if we have to perform many write operations on our database. But in fact, CSV and SQLite could be our choice too. Postgres is the slowest option, but there are ways to solve this, like sending async requests to a dedicated database server.
Read operations combined.
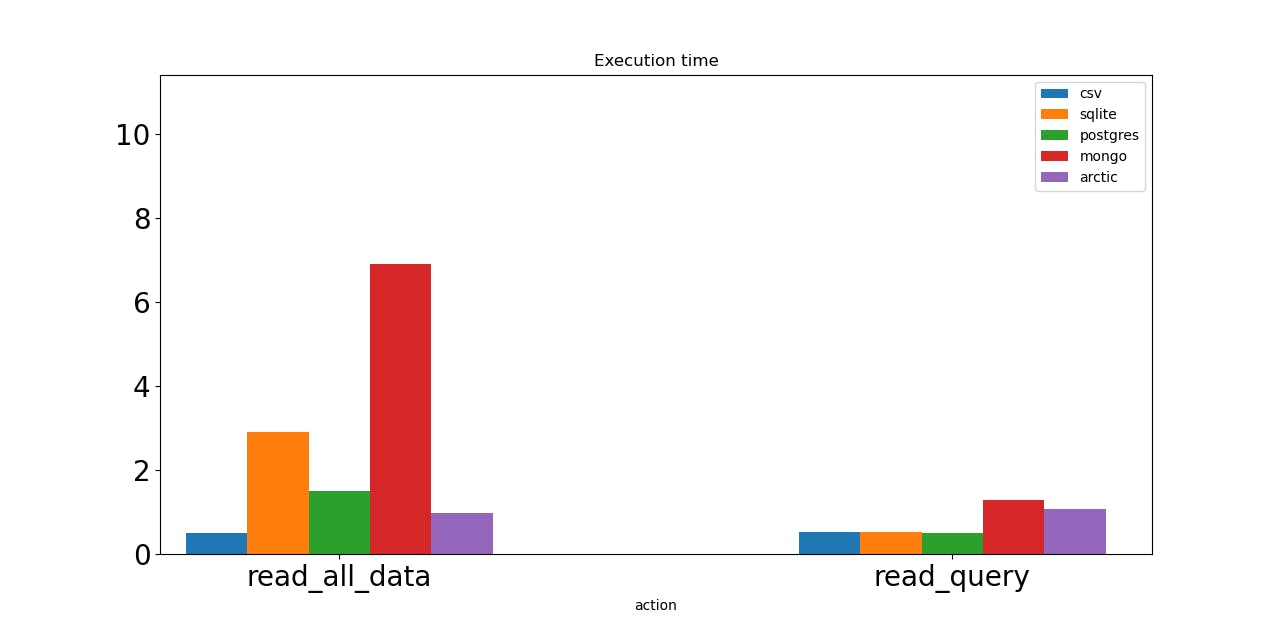
Postgres looks like a good choice here. Of course, CSV files are even faster, but CSV is not an actual database. Arctic looks like an excellent option to take into consideration. Mongo is the slowest one.
Some final thoughts. CSV and SQLite are not production-ready choices in many cases, but for a bunch of small/medium projects, they can be easy. Postgres has a slow write time, so it doesn’t look like an option for storing market data. Mongo and Arctic can be good options if we talk about a vast dataset that can not be stored in a plain CSV file.
Github repo with the code.

#python #databases #sql #nosql #market-data